|
|
| (11 intermediate revisions by 2 users not shown) |
| Line 3: |
Line 3: |
| An XML document can be uploaded to the eXist database even if the document is not valid according to the schema used. However it is mandatory that the document is well formed, otherwise errors will occur when trying to store the document. | | An XML document can be uploaded to the eXist database even if the document is not valid according to the schema used. However it is mandatory that the document is well formed, otherwise errors will occur when trying to store the document. |
|
| |
|
| But before the documents can be stored, a closer look at the collection structure within eXist is needed. The reBiND Framework depends on two collections for managing the different data projects. One of the collections is for the unpublished data projects, which are still being corrected, reviewed or otherwise prepared for publication. The other collection is for the published projects, which can be publicly searched and accessed. Within this document they will be referred to as ''unpublished'' and ''published''. Both of these collections are located in the root collection of eXist. Within these collections are the collection for the individual data projects. Having the two collections for unpublished and published data projects makes the security configuration also quite easy, since the security settings for these two collections are automatically inherited by data projects within these. | | But before the documents can be stored, a closer look at the collection structure within eXist is needed. The [[Glossary|reBiND Framework]] depends on two collections for managing the different data projects. One of the collections is for the unpublished data projects, which are still being corrected, reviewed or otherwise prepared for publication. The other collection is for the published projects, which can be publicly searched and accessed. Within this document they will be referred to as ''unpublished'' and ''published''. Both of these collections are located in the root collection of eXist. Within these collections are the collection for the individual data projects. Having the two collections for unpublished and published data projects makes the security configuration also quite easy, since the security settings for these two collections are automatically inherited by data projects within these. |
|
| |
|
| Instructions on how to create projects via the reBiND user interface have been desctibed in the [Data_upload_to_rebind_framework data archiving section]. | | Instructions on how to create projects via the reBiND user interface have been described in the [[Data_upload_to_rebind_framework|data archiving section]]. |
|
| |
|
| The collection structure of eXist, showing the unpublished and published project collections is shown below: | | The collection structure of eXist, showing the unpublished and published project collections is shown below: |
| Line 37: |
Line 37: |
| </pre> | | </pre> |
|
| |
|
| The majority of the database administration can be done through the eXist Java webstart client. For example, the client can be used to add new user accounts, modify permissions to different database collections and delete/edit/query the data. | | The majority of database administration can be done through the eXist Java webstart client. For example, the client can be used to add new user accounts, modify permissions for different database collections and delete/edit/query the data. |
|
| |
|
| ==User management== | | ==User management== |
| Line 54: |
Line 54: |
|
| |
|
| ===Writing Custom Correction Modules=== | | ===Writing Custom Correction Modules=== |
| A Correction Module is a Java Class which implements a specific Java Interface. It is possible to extend the correction manager by adding a new module (this should implement the class [http://ww2.biocase.org/svn/rebind/trunk/reBiND-CorrectionManager/src/org/bgbm/rebind/correction/modules/ Module]. A new module can be added to take care of a specific problem for the XML documents of the particular reBiND Instance, by writing a new class implementing the interface and putting the compiled class into a specific folder. The eXist server should be restarted but does not have to be rebuilt, which makes it very easy to add new correction modules. This was also one of the reasons why the corrections are done in Java code and not in XQuery. Also Java is much more widely used and understood than XQuery. Furthermore the Correction Manager could be used in stand-alone mode, either by creating an independent GUI tool or by calling the appropriate correction functions via the Command Line. This would require the ABCD data file and the configuration file (specifiying the correction modules to be run) to be specified and then calling the startCorrection method in the CorrectionManager class. | | A Correction Module is a Java Class which implements a specific Java Interface. It is possible to extend the correction manager by adding a new module (this should implement the class [http://ww2.biocase.org/svn/rebind/trunk/reBiND-CorrectionManager/src/org/bgbm/rebind/correction/modules/ Module]). |
|
| |
|
| ===Modifying the correction configuration file=== | | {{CodeExample|lang=Java| 1= |
| | package org.bgbm.rebind.correction.modules; |
|
| |
|
| = Modules for the XML Correction Manager =
| | import java.io.File; |
| When the user starts the correction of an XML file, a specific correction configuration has to be selected. The web interface of the Correction Manager will offer a list of all correction config files in the correction config directory. A correction config file, is an XML file which is valid to a specific schema. It specifies what correction modules will be called, in what order and with what parameters. The structure of such a file is relatively simple:
| |
| <syntaxhighlight>
| |
| <modules xmlns="http://rebind.bgbm.org/modules" name="configuration-name">
| |
| <module name="module-name" description="module-description">
| |
| <setting name="module-setting-name" value="module-setting-value"/>
| |
| </module>
| |
| <setting name="general-setting-name" value="general-setting-value"/>
| |
| </modules>
| |
| </syntaxhighlight>
| |
|
| |
|
| The root element is <code>modules</code>. The <code>name</code> attribute is optional. It is the name with which the module will be displayed in the web interface of the Correction Manager. | | public interface Module { |
| | public String process(File inputFile, File outputFile, String[][] settings); |
| | } |
| | |description=The Java code of the Module Interface.}} |
|
| |
|
| There can be several <code>module</code> elements within the element <code>modules</code>.
| | A new module can be added to take care of a specific problem for the XML documents of the particular reBiND Instance, by writing a new class implementing the interface and putting the compiled class into a specific folder. The eXist server should be restarted but does not have to be rebuilt, which makes it very easy to add new correction modules. This was also one of the reasons why the corrections are done in Java code and not in XQuery. Also Java is much more widely used and understood than XQuery. Furthermore the Correction Manager could be used in stand-alone mode, either by creating an independent GUI tool or by calling the appropriate correction functions via the Command Line. This would require the ABCD data file and the configuration file (specifying the correction modules to be run) to be specified and then calling the startCorrection method in the CorrectionManager class. |
|
| |
|
| Each <code>module</code> element must have a <code>name</code> attribute which specifies the name of the module to be loaded. This should either be the complete name of a Java class which implements the <code>Module</code> interface or the name specified within the method <code>getName()</code> of that class.
| | ===Modifying the correction configuration file=== |
| | | The correction configuration file specifies which correction modules are run and in what order. It is an XML file stored in a special collection within eXist - the default location is /db/rebind/correction and the default name is default-correction.xml. By creating different configuration files the user can specify different checks, for example the default configuration checks for all possible errors that have been seen in ABCD files, in another configuration the user might just want to check if the ISO dates are formatted correctly. Details of how to modify the configuration file and an explanation of the function of the implemented modules are [[Correction Modules|described here]]. |
| The <code>description</code> is optional and is used to distinguish different instances of the same module which are run with different settings.
| |
| | |
| Each <code>module</code> element can have any number of <code>setting</code> elements. Each <code>setting</code> element has mandatory attributes for the setting <code>name</code> and <code>value</code>. What settings are used for each module is specified in the module descriptions below.
| |
| | |
| The <code>modules</code> element can also have <code>setting</code> elements. These general settings are also accessible by the module and are overwritten if a setting with the same name is specified in the <code>module</code> element.
| |
| __TOC__
| |
| == ElementTextReplacer == | |
| ''What it does'': Replaces the text content of specific elements according to specific rules.
| |
| | |
| ''Full Name'': <code>org.bgbm.rebind.correction.modules.ElementTextReplacer</code>
| |
| | |
| ''Settings'':
| |
| : '''address'''
| |
| :: The name (including element prefix) of the element whose text should be replaced. Or an XPath expression pointing to the element. If the value is interpreted as a name or as an XPath depends on the attribute <code>isXPath</code>.
| |
| :: ''Mandatory'': yes
| |
| :: ''Example Values'': <code>abcd:Sex</code> or <code>//abcd:RecordBasis[matches(.,'^Specimen$')]</code>
| |
| | |
| : '''isXPath'''
| |
| :: A flag indicating if the <code>address</code> element contains an XPath expression or just the name of an element.
| |
| :: ''Mandatory'': no
| |
| :: ''Default Value'': <code>false</code>
| |
| :: ''Allowed Values'': <code>true</code> or <code>false</code>
| |
| | |
| : '''key'''
| |
| :: The part of the content that should be replaced. This could either be plain text or a RegEx, depending on the attribute <code>isRegEx</code>. Regardless whether it is plain text or an attribute, it could several keys to be replaced or just one, depending on the attribute <code>isBatch</code>. If the batch mode is used, the character or string with which the different parts are separated can be specified in the attribute <code>splitter</code>.
| |
| :: ''Mandatory'': yes
| |
| :: ''Example Values'': <code>Hello World</code> (plain text), <code>(H[ea]llo World)(\!?)</code> (RegEx), <code>Hello World;Lorem Ipsum</code> (plain text, Batch mode with ';' as splitter), <code>H[ea]llo World\!?;[Ll]orem [iI]psum</code> (RegEx, Batch mode with ';' as splitter),
| |
| | |
| : '''value'''
| |
| :: The new content with which the content specified in <code>key</code> will be replaced. This could either be plain text or a RegEx, depending on the attribute <code>isRegEx</code>. Regardless whether it is plain text or an attribute, it could several keys to be replaced or just one, depending on the attribute <code>isBatch</code>. If the batch mode is used, the character or string with which the different parts are separated can be specified in the attribute <code>splitter</code>. If the batch mode is used, the key fragments will be replaced by the corresponding value fragments (e.g. the third key fragment will be replaced by third value fragment). Therefore the number of fragments must be the same for key and value, otherwise the replacement will stop after the number of fragments in the smaller one.
| |
| :: ''Mandatory'': yes
| |
| :: ''Example Values'': <code>Hello World again</code> (plain text), <code>$1 again $2</code> (RegEx), <code>Hello World again;Lorem ipsum dolor sit amet</code> (plain text, Batch mode with ';' as splitter), <code>$1 again $2;$& dolor sit amet</code> (RegEx, Batch mode with ';' as splitter),
| |
| | |
| : '''isRegEx'''
| |
| :: A flag indicating if the <code>key</code> and the <code>value</code> elements are regular expressions or just plain text.
| |
| :: ''Mandatory'': no
| |
| :: ''Default Value'': <code>false</code>
| |
| :: ''Allowed Values'': <code>true</code> or <code>false</code>
| |
| | |
| : '''isBatch'''
| |
| :: A flag indicating if the <code>key</code> and the <code>value</code> elements contain just one fragment which is supposed to be replaced, or several. If it is true, the character or string with which the different fragments of <code>key</code> and the <code>value</code> elements are separated can be specified in the attribute <code>splitter</code>.
| |
| :: ''Mandatory'': no
| |
| :: ''Default Value'': <code>false</code>
| |
| :: ''Allowed Values'': <code>true</code> or <code>false</code>
| |
| | |
| : '''splitter'''
| |
| :: The character or string with which the <code>key</code> and the <code>value</code> elements are broken into their fragments, if they are in batch mode. The splitting is done using the function [http://docs.oracle.com/javase/6/docs/api/java/lang/String.html#split%28java.lang.String%29 String.split(String)], which interprets the parameter string as a regular expression. This could cause errors when the splitter contains characters with syntactical meaning in RegEx, like <code><setting name="splitter" value="."/></code> which would cause any character to be matched and therefor only returning empty fragments.
| |
| :: ''Mandatory'': no
| |
| :: ''Default Value'': <code>;</code>
| |
| :: ''Example Values'': <code>,</code> or <code>\.</code>
| |
| | |
| ''Examples'':
| |
| <syntaxhighlight>
| |
| <module name="org.bgbm.rebind.correction.modules.ElementTextReplacer" description="replaces 'Specimen'">
| |
| <setting name="address" value="//abcd:RecordBasis[matches(.,'^Specimen$')]"/>
| |
| <setting name="isXPath" value="true"/>
| |
| <setting name="key" value="^(Specimen)$"/>
| |
| <setting name="value" value="Preserved$1"/>
| |
| <setting name="isRegEx" value="true"/>
| |
| <setting name="isBatch" value="false"/>
| |
| <setting name="splitter" value=";"/>
| |
| </module>
| |
| <module name="org.bgbm.rebind.correction.modules.ElementTextReplacer" description="corrects abcd:Sex">
| |
| <setting name="address" value="abcd:Sex"/>
| |
| <setting name="isXPath" value="false"/>
| |
| <setting name="key" value="female;male;hermaphrodite"/>
| |
| <setting name="value" value="F;M;X"/>
| |
| <setting name="isRegEx" value="false"/>
| |
| <setting name="isBatch" value="true"/>
| |
| <setting name="splitter" value=";"/>
| |
| </module>
| |
| <module name="org.bgbm.rebind.correction.modules.ElementTextReplacer" description="corrects abcd:Rank">
| |
| <setting name="address" value="abcd:Rank"/>
| |
| <setting name="isXPath" value="false"/>
| |
| <setting name="key" value="[f.];[subvar.];[var.]"/>
| |
| <setting name="value" value="f.;subvar.;var."/>
| |
| <setting name="isRegEx" value="false"/>
| |
| <setting name="isBatch" value="true"/>
| |
| <setting name="splitter" value=";"/>
| |
| </module>
| |
| <module name="org.bgbm.rebind.correction.modules.ElementTextReplacer" description="corrects abcd:Rank">
| |
| <setting name="address" value="//abcd:Rank[matches(.,'^(f|var)$')]"/>
| |
| <setting name="isXPath" value="true"/>
| |
| <setting name="key" value="^f$;^var$"/>
| |
| <setting name="value" value="f.;var."/>
| |
| <setting name="isRegEx" value="true"/>
| |
| <setting name="isBatch" value="true"/>
| |
| <setting name="splitter" value=";"/>
| |
| </module>
| |
| </syntaxhighlight>
| |
| | |
| | |
| == EmptyElementDeleter ==
| |
| ''What it does:'' Removes empty elements which have neither text content (except white spaces) nor child elements nor attributes. Currently there is a hardcoded exception regarding the attributes. If the only attribute is <code>abcd:language</code> then the element will be deleted as well. Such exceptions will be adjustable via the settings in the future.
| |
| | |
| ''Full Name:'' <code>org.bgbm.rebind.correction.modules.EmptyElementDeleter</code>
| |
| | |
| ''Settings:'' none
| |
| | |
| ''Example:''
| |
| <syntaxhighlight>
| |
| <module name="org.bgbm.rebind.correction.modules.EmptyElementDeleter" description="first iteration"/>
| |
| </syntaxhighlight>
| |
| | |
| | |
| == ElementDeleter ==
| |
| ''What it does:'' Deletes specific elements including all its content and child elements.
| |
| | |
| ''Full Name:'' <code>org.bgbm.rebind.correction.modules.ElementDeleter</code>
| |
| | |
| ''Settings:''
| |
| : '''xpath'''
| |
| :: The XPath address of the element(s) to be removed. Also works for attributes.
| |
| :: ''Mandatory:'' yes
| |
| :: ''Example Values:'' <code>//abcd:LogoURI</code> or <code>//abcd:TelephoneNumber[abcd:Device="Fax"]</code>
| |
| | |
| ''Examples:''
| |
| <syntaxhighlight>
| |
| <module name="org.bgbm.rebind.correction.modules.ElementDeleter" description="delete abcd:language attributes">
| |
| <setting name="xpath" value="//*/@abcd:language"/>
| |
| </module>
| |
| </syntaxhighlight>
| |
| | |
| | |
| == ElementRenamer ==
| |
| ''What it does:''
| |
| | |
| ''Full Name:'' <code>org.bgbm.rebind.correction.modules.ElementRenamer</code>
| |
| | |
| ''Settings:''
| |
| : '''xpath'''
| |
| :: The XPath address of the element(s) to be renamed. Also works for attributes.
| |
| :: ''Mandatory:'' yes
| |
| :: ''Example Values:'' <code>//abcd:LogoURI</code> or <code>//abcd:TelephoneNumber[abcd:Device="Fax"]</code>
| |
| | |
| : '''newName'''
| |
| :: The new name of the element, without namepsace prefix.
| |
| :: ''Mandatory:'' yes
| |
| :: ''Example Values:'' <code>newElementName</code>
| |
| | |
| : '''useOldNamespace'''
| |
| :: A flag indicating if the old namespace (and namespace prefix) of the element should be used after renaming as well.
| |
| :: ''Mandatory:'' no
| |
| :: ''Default Value:'' <code>true</code>
| |
| :: ''Allowed Values:'' <code>true</code> or <code>false</code>
| |
| | |
| : '''newNamespace'''
| |
| :: The namespace url of the new namespace, if <code>useOldNamespace</code> is set to <code>false</code>.
| |
| :: ''Mandatory:'' no
| |
| :: ''Default Value:'' ''(empty string)''
| |
| :: ''Example Values:'' <code><nowiki>http://example.com/ns/xyz</nowiki></code>
| |
| | |
| : '''newNamespacePrefix'''
| |
| :: The namespace prefix of the new namespace, if <code>useOldNamespace</code> is set to <code>false</code>. If the colon at the end is missing, it will be added automatically.
| |
| :: ''Mandatory:'' no
| |
| :: ''Default Value:'' ''(empty string)''
| |
| :: ''Example Values:'' <code>xyz:</code>
| |
| | |
| ''Examples:''
| |
| <syntaxhighlight>
| |
| <module name="org.bgbm.rebind.correction.modules.ElementRenamer" description="rename abcd:language attributes">
| |
| <setting name="xpath" value="//*/@abcd:language"/>
| |
| <setting name="newName" value="language"/>
| |
| <setting name="useOldNamespace" value="false"/>
| |
| <setting name="newNamespace" value=""/>
| |
| <setting name="newNamespacePrefix" value=""/>
| |
| </module>
| |
| <module name="org.bgbm.rebind.correction.modules.ElementRenamer" description="rename wrong ISO Dates">
| |
| <setting name="xpath" value="//abcd:ISODateTimeBegin[not(matches(.,'^(\d\d\d\d(\-(0[1-9]|1[012])(\-((0[1-9])|1\d|2\d|3[01])(T(0\d|1\d|2[0-3])(:[0-5]\d){0,2})?)?)?|\-\-(0[1-9]|1[012])(\-(0[1-9]|1\d|2\d|3[01]))?|\-\-\-(0[1-9]|1\d|2\d|3[01]))$'))]"/>
| |
| <setting name="newName" value="DateText"/>
| |
| <setting name="useOldNamespace" value="true"/>
| |
| </module>
| |
| </syntaxhighlight>
| |
| | |
| | |
| == DummyModule ==
| |
| ''What it does:'' Waits 1-11 seconds before returning a quote from either the homicidal computer HAL 9000 from the movie "2001: A Space Odyssey" or the maniacally depressed robot Marvin from the book/movie "The Hitchhiker's Guide to the Galaxy". This module does not alter the XML code in any way, it only sends the quote back to the Correction Manager. It is only used for testing purposes.
| |
| | |
| ''Full Name:'' <code>org.bgbm.rebind.correction.modules.DummyModule</code>
| |
| | |
| ''Settings:'' none
| |
| | |
| ''Examples:''
| |
| <syntaxhighlight>
| |
| <module name="org.bgbm.rebind.correction.modules.DummyModule" description="just wait a bit for a snappy robot remark" />
| |
| <module name="org.bgbm.rebind.correction.modules.DummyModule" description="Play it once again, Marvin, for old times' sake." />
| |
| </syntaxhighlight>
| |
| | |
| | |
| == Work in Progress ==
| |
| These modules are currently in the making. So some of these descriptions might not reflect the current state of development.
| |
| | |
| === ABCDDateCorrector ===
| |
| ''What it does:'' Checks the dates in the elements <code>abcd:ISODateTimeBegin</code> within <code>abcd:Date</code> and <code>abcd:DateTime</code>. If they are not formatted according to the ISO norm it tries to parse and fix them or renames the element to <code>abcd:DateText</code>. However if there are any <code>abcd:DateText</code> elements which are correctly formatted or can be converted, it will make them into <code>abcd:ISODateTimeBegin</code> elements.
| |
| | |
| ''Full Name:'' <code>org.bgbm.rebind.correction.modules.ABCDDateCorrector</code>
| |
| | |
| ''Settings:'' none
| |
| | |
| ''Examples:''
| |
| <syntaxhighlight>
| |
| <module name="org.bgbm.rebind.correction.modules.ABCDDateCorrector" description="fixing the dates" />
| |
| </syntaxhighlight>
| |
| | |
| | |
| === SimpleCountryCodeChecker ===
| |
| ''What it does:'' Compares the content of the <code>abcd:ISO3166Code</code> element with a list of Country Codes provided by Java and warns if it doesn't occur there. Also has some hardcoded exceptions for the commonly used but unspecified codes:
| |
| ZZ Unknown
| |
| XA Unknown or unspecified Africa
| |
| XB Unknown or unspecified Middle and South America
| |
| XC Unknown or unspecified Asia
| |
| XD Unknown or unspecified Australia and Oceania
| |
| XE Unknown or unspecified Europe
| |
| XF Unknown or unspecified North America
| |
| | |
| ''Full Name:'' <code>org.bgbm.rebind.correction.modules.SimpleCountryCodeChecker</code>
| |
| | |
| ''Settings:'' none
| |
| | |
| ''Examples:''
| |
| <syntaxhighlight>
| |
| <module name="org.bgbm.rebind.correction.modules.SimpleCountryCodeChecker" description="checking the country codes" />
| |
| </syntaxhighlight>
| |
|
| |
|
| ===[[Correction Modules]]=== | | ==Using a different metadata format== |
| ** ([[Architecture-Concept#Automated_Corrections|How to modify the correction configuration file]])
| |
|
| |
|
| ** Using a different metadata format ([[Metadata|Discussion of different Metadata standards]])
| | We chose Ecological Markup Language (EML) for creating additional metadata to associate with our published ABCD datasets. EML is used by researchers to document a typical dataset in the ecological sciences. We chose to use [[Ecologial_Metadata_Language| a sub-set of EML to describe the core features of our datasets]]. We also investigated [[Metadata| several other Metadata standards]], before selecting EML as the most appropriate for our purpose. |
Administration
An XML document can be uploaded to the eXist database even if the document is not valid according to the schema used. However it is mandatory that the document is well formed, otherwise errors will occur when trying to store the document.
But before the documents can be stored, a closer look at the collection structure within eXist is needed. The reBiND Framework depends on two collections for managing the different data projects. One of the collections is for the unpublished data projects, which are still being corrected, reviewed or otherwise prepared for publication. The other collection is for the published projects, which can be publicly searched and accessed. Within this document they will be referred to as unpublished and published. Both of these collections are located in the root collection of eXist. Within these collections are the collection for the individual data projects. Having the two collections for unpublished and published data projects makes the security configuration also quite easy, since the security settings for these two collections are automatically inherited by data projects within these.
Instructions on how to create projects via the reBiND user interface have been described in the data archiving section.
The collection structure of eXist, showing the unpublished and published project collections is shown below:
/db/
├─ (eXist default)
├─ unpublished/
│ ├─ (data-project-name 1)/
│ │ ├─ data.xml
│ │ ├─ metadata.xml
│ │ ├─ original-data.xls
│ │ └─ images/
│ │ ├─ image_001.jpg
│ │ ├─ image_002.jpg
│ │ └─ ...
│ └─ (data-project-name 2)/
│ └─ ...
└─ published/
└─ (data-project-name 3)/
├─ data.xml
├─ metadata.xml
├─ original-data.xls
├─ images/
│ ├─ image_001.jpg
│ ├─ image_002.jpg
│ └─ ...
└─ multimedia/
├─ movie1.mov
├─ movie2.avi
└─ ...
The majority of database administration can be done through the eXist Java webstart client. For example, the client can be used to add new user accounts, modify permissions for different database collections and delete/edit/query the data.
User management
Users can be created via the eXist Java admin client. For example creating a new user for the contributing scientist is shown in the screenshot below.
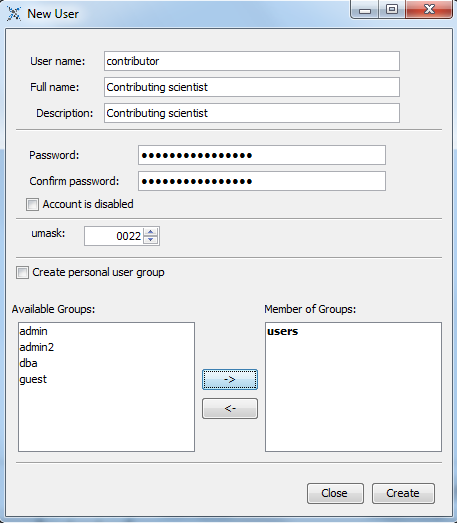
In the above example the 'contributing scientist' is allocated to the group 'users', so the /db/unpublished/ directory within the eXist database should be made accessible to the group 'users'.
Correction Manager
Though all of the corrections and modifications to the data document could be done using XQuery and the XQuery Update Facility, it was decided to not have the corrections run in XQuery directly. The Correction Manager is written in Java. It is only loosely coupled to eXist in order to make the Framework more modular. Instead of a document being directly accessed within eXist by the Correction Manager, it will be exported by the custom XQuery function to a regular XML file on the file system of the server. This file is then handed over to the Correction Manager. The source code for the eXist module that interacts with the Correction Manager is available from our subversion repository.
The actual corrections are not done by the Correction Manager, but by individual Correction Modules which are managed by the Correction Manager. The source code for the Correction Manager and correction modules is available from our subversion repository.
Writing Custom Correction Modules
A Correction Module is a Java Class which implements a specific Java Interface. It is possible to extend the correction manager by adding a new module (this should implement the class Module).
package org.bgbm.rebind.correction.modules;
import java.io.File;
public interface Module {
public String process(File inputFile, File outputFile, String[][] settings);
}
The Java code of the Module Interface.
A new module can be added to take care of a specific problem for the XML documents of the particular reBiND Instance, by writing a new class implementing the interface and putting the compiled class into a specific folder. The eXist server should be restarted but does not have to be rebuilt, which makes it very easy to add new correction modules. This was also one of the reasons why the corrections are done in Java code and not in XQuery. Also Java is much more widely used and understood than XQuery. Furthermore the Correction Manager could be used in stand-alone mode, either by creating an independent GUI tool or by calling the appropriate correction functions via the Command Line. This would require the ABCD data file and the configuration file (specifying the correction modules to be run) to be specified and then calling the startCorrection method in the CorrectionManager class.
Modifying the correction configuration file
The correction configuration file specifies which correction modules are run and in what order. It is an XML file stored in a special collection within eXist - the default location is /db/rebind/correction and the default name is default-correction.xml. By creating different configuration files the user can specify different checks, for example the default configuration checks for all possible errors that have been seen in ABCD files, in another configuration the user might just want to check if the ISO dates are formatted correctly. Details of how to modify the configuration file and an explanation of the function of the implemented modules are described here.
Using a different metadata format
We chose Ecological Markup Language (EML) for creating additional metadata to associate with our published ABCD datasets. EML is used by researchers to document a typical dataset in the ecological sciences. We chose to use a sub-set of EML to describe the core features of our datasets. We also investigated several other Metadata standards, before selecting EML as the most appropriate for our purpose.
